§摘要 (Abstract)
现有的指令式视频编辑(Instruction-based Video Editing, IVE)数据集通常局限于单任务外观级编辑,无法满足现实场景中复杂的创作需求。为弥合这一鸿沟,作者提出 Goku——一个包含 200 万高质量、指令对齐视频编辑对的大规模数据集,是首个将任务边界从基本外观编辑扩展至多任务与结构化操控(例如对主体运动的精确控制)的数据集。
为应对复杂任务的数据合成挑战,本文设计了一个高效的数据合成流水线,将复杂编辑分解为可控的子问题;并引入渐进式过滤系统贯穿整个流程保证数据可靠性。此外,作者探索了 Goku 上的最优网络结构,提出 Goku-Edit:以 MLLM 作为文本编码器,采用解耦的双分支设计——一个专用掩码分支处理结构控制,让主分支专注外观渲染。
作者还推出了Goku-Bench——一个包含 1000 个人工核验测试用例与 7 个新颖编辑专属指标的综合基准。评测显示,Goku-Edit 在指令跟随方面较其他开源模型取得高达 +8% 的提升。
1引言 (Introduction)
生成式 AI 的迅速发展重塑了数字内容创作,正从简单的视频合成迈向更具挑战的领域。指令式视频编辑 (IVE) 通过合成视频三元组,为用户提供了直观灵活的接口,使专业级视频制作走向大众化。然而当前 SOTA 方法仍局限于单任务、外观级的修改(如物体移除、单属性变更)。
1.1 现有数据集的关键缺陷
- Ditto 提高了质量控制,但严重偏向风格迁移,任务多样性不足。
- 并行工作 OpenVE-3M 加强了过滤严格度,但仍局限于外观级编辑,未涉及结构化与多任务编辑。
- 已有数据集普遍过度简化编辑任务,忽视了真实场景中所需的复杂结构变换与同时多任务编辑需求。
1.2 Goku 的定位
Goku 首次显式地将 IVE 数据集从孤立任务集合升级为一个覆盖广泛挑战的综合谱系:

1.3 主要贡献
综合数据集
Goku 是迄今最大的 IVE 数据集,200 万高质量视频对,首次覆盖复杂结构与多任务编辑。
鲁棒数据流水线
可扩展的自动化数据流水线,配备渐进式过滤系统,保证语义精确性与时序一致性。
多能编辑模型
Goku-Edit 通过 MLLM 文本编码器与掩码预测新分支,将高层语义推理与精确空间操控相桥接。
严谨基准
Goku-Bench 提供 1000 个人工核验用例、7 个专用指标,为评估复杂视频编辑树立新标准。
2相关工作 (Related Work)
2.1 指令式视频编辑方法
- InsV2V:提出合成视频三元组的范式以缓解配对训练数据稀缺;InsViE 进一步扩大规模。
- AnyV2V:无需训练的即插即用框架,将编辑分解为首帧修改与 I2V 传播。
- StableV2V:聚焦形状与时序一致性。
- Omni-Video:将 MLLM 与视频扩散模型连接,实现多样视频任务。
- LucyEdit:借助大规模训练获得高视觉保真度与时序一致性。
然而上述方法多聚焦于单任务外观编辑,在复杂结构化编辑上仍力不从心。
2.2 指令式视频编辑数据集对比
| 维度 | Goku (本文) | Ditto | Señorita-2M | InsViE | OpenVE-3M |
|---|---|---|---|---|---|
| 数据规模 | 2M | 1M | 2M | 1M | 3M |
| 分辨率 | 720p | 720p | 336×592~1120×1984 | 576p | 720p |
| 每视频帧数 | 65~129 | 101 | 33~64 | 25 | 65~129 |
| 基础编辑 | ✓ | ✓ | ✓ | ✓ | ✓ |
| 相机运动 | ✓ | ✗ | ✗ | ✗ | ✓ |
| 主体运动 | ✓ | ✗ | ✗ | ✗ | ✗ |
| 参考图编辑 | ✓ | ✗ | ✗ | ✗ | ✗ |
| 多任务编辑 | ✓ (2-5 任务) | ✗ | ✗ | ✗ | ✗ |
| MLLM 依赖 | Gemini 2.5-Pro | Qwen-VL | Llama 3.2-8B | GPT-4o | GPT-4o |
| 配套 Benchmark | ✓ Goku-Bench | ✗ | ✗ | ✗ | ✓ OpenVE-Bench |
3Goku 数据集
3.1 视频预处理 (Video Pre-Processing)
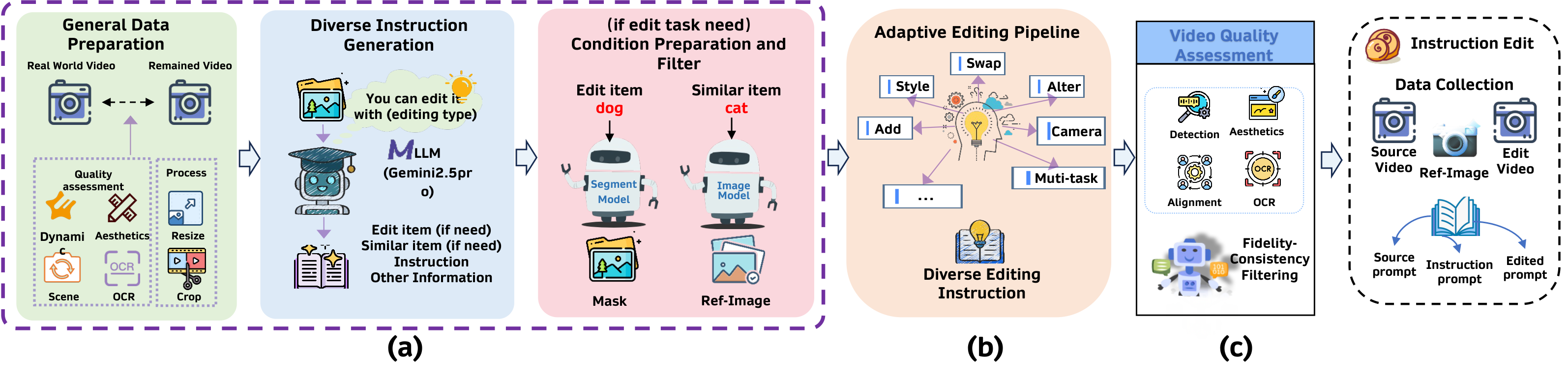
视频质量评估与过滤
起始于 Koala-36M 提供的原始视频,作者从中筛选出 100 万高质量视频片段,过滤流水线包括:
每段视频被裁剪为 3 到 10 秒以突出连贯的动作与场景。
MLLM 驱动的指令生成
- 对 Add / Remove / Swap / Subject Movement 任务:Gemini2.5-Pro 分析视频内容,识别可操作目标(覆盖 200+ 类),输出结构化编辑指令与物体标签。
- Style Transfer 覆盖 100+ 风格;Camera Movement 覆盖 20+ 运动模式。
- 对多任务与结构化编辑,通过精心设计的提示模板,防止任务冲突(例如同时"移除狗"与"给狗戴帽子")。
参考图/掩码抽取
基于物体标签,采用 Grounded-SAM2 抽取时序掩码;再由 Gemini2.5-Pro 分析编辑区域的光照与物体姿态,生成对应环境下相似物体的参考图,作为空间与外观条件。
3.2 各任务数据生成 (Data Generation)
外观编辑 (Appearance Editing)
- Add & Remove:利用二者的对偶性——先用 Minimax-Remover 做无痕移除得到 Remove 样本,再交换原始与移除后视频角色即可获得自然的 Add 样本,避免"漂浮物"和不合理遮挡。
- Swap & Attribute Alter:将源视频、Grounded-SAM2 掩码与 Flux 生成的参考图共同输入 VACE,在掩码区域内进行语义替换或属性修改,同时保留非编辑区域。
- Style Transfer:分解为三步——① Flux 对首帧风格化;② 抽取每帧深度图作为几何约束;③ 将风格化首帧与深度序列送入 VACE 沿时间轴传播风格,从而保持场景几何一致,避免闪烁与风格漂移。
结构化编辑 (Structural Editing)
本文首次为 Subject Movement 与 Camera Movement 构建大规模配对数据。
- Subject Movement:分为动作变化 (action variation) 与位置变化 (position variation) 两个子问题。
- 动作变化:Gemini2.5-Pro 生成同一主体的两种动作描述(如 walking → running),使用 Wan2.2 合成成对视频,主体身份与背景保持一致而动作不同。
- 位置变化:先用 Flux 在首帧将目标物体移到新坐标,再用 Wan2.2 将该重定位首帧扩展成时序连贯视频,从而将视频级重定位化简为图像编辑 + 条件视频生成。
- Camera Movement:基于 Gemini2.5-Pro 生成的指令与场景描述,使用 RecamMaster 合成相机运动视频对。对复杂运动(如 pan-left-then-push-in)拆解为 20+ 基础运动模式的顺序组合。
多任务编辑 (Multi-Task Editing)
基于 MLLM 生成的任务分解,逐步执行单任务序列,前一步的输出作为后一步的输入,整体质量由渐进式过滤系统保障。
参考图编辑 (Reference-based Editing)
Reference Swap / Add 需要模型依据用户参考图执行编辑。由于参考图是用掩码从原视频裁剪,模型可能退化为像素级复制。因此作者采用 Flux 对参考图重绘,提供带姿态偏移、光照变化与背景替换的扰动参考图。
3.3 渐进式过滤系统 (Progressive Filtering System)
源视频过滤
视频预处理阶段:美学评分、运动动态分析、镜头切换检测、OCR 水印移除,最后由 Gemini2.5-Pro 做内容丰富度筛查,得到共享的 100 万高质量源片段。
条件校验
数据生成前校验中间表示:以 IoU 阈值检验掩码完整性;Gemini2.5-Pro 校验编辑目标与指令的语义一致性、参考图的视觉合理性;不合格样本直接丢弃,避免昂贵合成阶段的浪费。
合成后校验
双层评估:低层视觉——帧间一致性、频域伪影检测、美学重打分;高层语义——由 Gemini2.5-Pro 评估编辑准确性与真实感。约 88% 的合成样本会被过滤,最终保留最高质量数据。
4Goku-Edit 模型
Goku-Edit 由三大核心组件构成:双分支模型架构、RoPE 对齐的空间交叉注意力、以及推理期的 SpatialCFG。
4.1 双分支模型架构 (Dual-Branch Architecture)
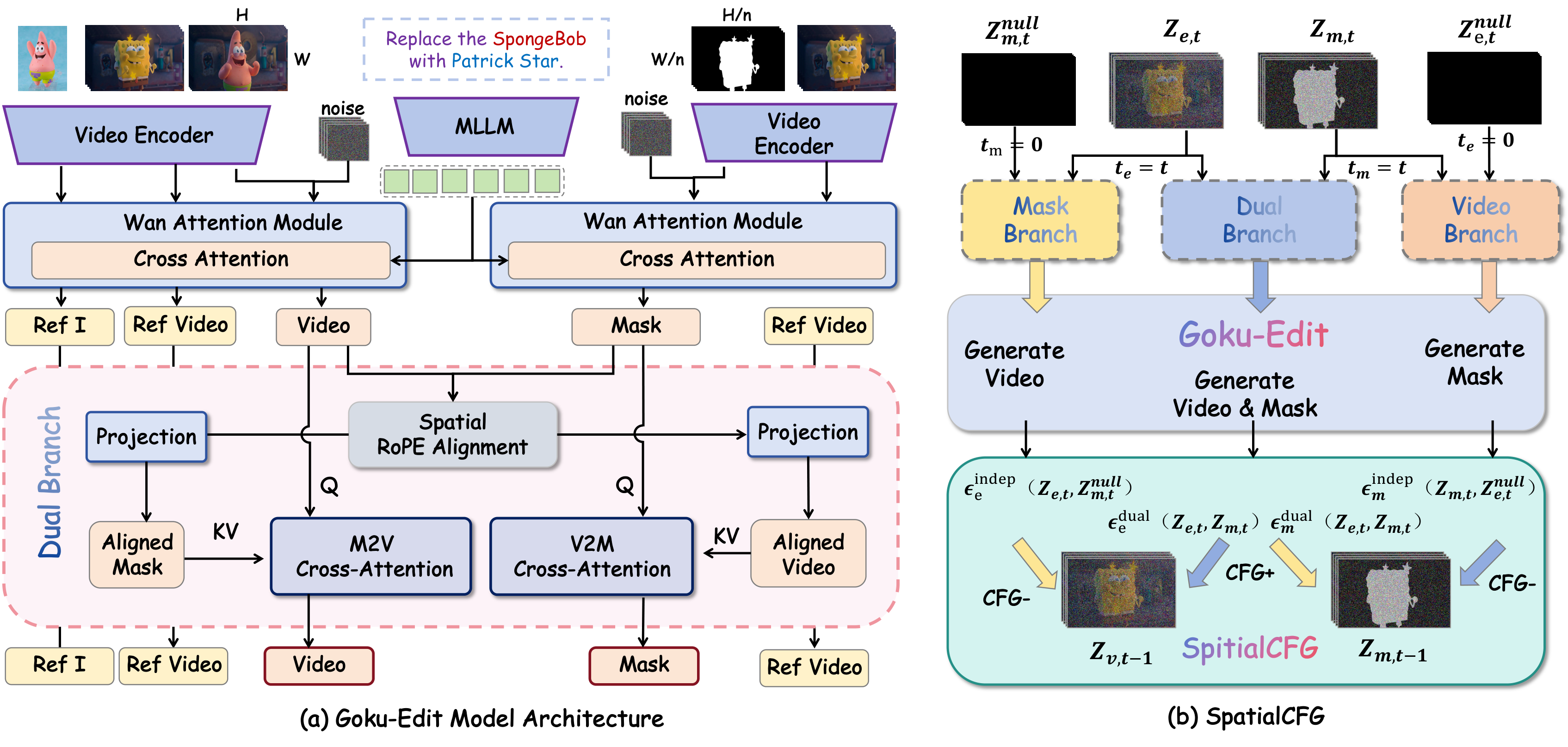
输入: Tp, Vs, Ir
输出: 编辑视频 Ve
基座: Wan2.2-5B
输入: Tp, 下采样源视频 Vd (1/n)
输出: 编辑区域掩码 M
基座: Wan2.2-5B
两分支基于预训练 Wan2.2-5B 改造。文本编码器采用冻结的 Qwen3VL-8B (MLLM),同时服务两条分支以增强复杂指令理解。VAE 将 Ir, Vs, Ve, Vd, M 编码为潜在表示 zr, zs, ze, zd, zm。
沿时间维拼接条件与噪声潜在,分别送入两分支预测噪声。
4.2 RoPE 对齐的空间交叉注意力
掩码分支运行于 1/n 空间分辨率,两分支的 token 对应不同离散坐标网格。RoPE 注意力权重依赖于相对偏移 j - k,若直接跨分辨率计算,会引入因网格不匹配导致的宏观偏移,进而在特征内积中注入不必要的旋转相位惩罚,抑制空间对应 token 之间的注意力。
基于 RoPE Scaling 的空间对齐
在计算 RoPE 之前,将掩码分支的位置索引乘以因子 n:将掩码 token 位置 (x, y) 映射到高分辨率坐标 (nx, ny),而不修改 RoPE 频率基。
⇒ 相对偏移 j - k' = (δx, δy)
宏观错位由此消除:δ=0 时旋转矩阵为 I,非重合 token 对的偏移仍与真实物理距离成比例,跨分辨率保留了 RoPE 的局部性偏置。
双向交叉注意力 (Bidirectional Cross-Attention)
- M2V (mask→video):ze 作 Query,对齐后的 zm 作 K/V,通过残差连接注入结构信号:
zeupdated = ze + Δze。 - V2M (video→mask):角色反转,同理
zmupdated = zm + Δzm。
4.3 空间增强 CFG (SpatialCFG)
标准文本 CFG 只放大文本条件信号,无法进一步强化掩码分支带来的空间约束,容易在复杂结构化编辑中产生边界漂移与"编辑外溢"。作者提出 SpatialCFG——一种免训练的推理期策略,通过对比"耦合预测"与"解耦基线"来显式放大跨分支空间约束:
- 启用双向交叉注意力时,两分支产生耦合预测
ε̂duale/m(z'e,t, z'm,t); - 禁用跨分支注意力并将对方输入替换为 null 潜在,得到解耦基线
ε̂indepe(z'e,t, znullm,t)与ε̂indepm(z'm,t, znulle,t);两基线均保留文本条件与分支内计算。
ε̃m = ε̂indepm + sm·(ε̂dualm − ε̂indepm) (3)
其中 se 抑制编辑区域外的意外修改,sm 精修掩码边界一致性。SpatialCFG 与文本 CFG 正交组合:
5Goku-Bench 基准
5.1 测试集构造
从 Koala-36M 精选 1000 段高质量、有挑战性的视频,选择标准包括分辨率 ≥720p、时长 3-10 秒、运动复杂度等。测试集覆盖:
- 多人场景、全身/半身人体主体;
- 动物(狗、猫、鲨鱼、鸟等)、常见物体(服装、车辆、建筑等)、自然景观(山川、河流、沙漠等);
- 特殊拍摄条件:低照度、快速运动主体、强烈相机抖动;
- 结构化编辑与多任务联合编辑等现有基准中欠代表的场景;
- 所有编辑指令均由人工撰写,保证多样性、准确性与合适的任务难度。
5.2 编辑专属指标 (7 Metrics)
Goku-Bench 提出 4 个通用编辑指标 + 3 个任务专属指标,均通过 Gemini2.5-Pro 或专家算法自动评估。
Physical Rule Fidelity 物理规则保真度
评估编辑结果在运动与交互层面是否符合真实世界物理规律,聚焦物理交互的合理性。
Spatial Relationship Accuracy 空间关系准确度
评估主体与场景之间的空间排布是否严格符合编辑指令。
Instruction Following 指令跟随度
综合评估模型对复杂多任务编辑指令的完整执行程度。
Overall Editing Quality 整体编辑质量
从视觉自然度与编辑一致性双视角进行整体评估。
Subject Motion 主体运动
用 Gemini2.5-Pro 打分主体运动轨迹的真实感与流畅度;与 PR(评估整体物理交互)区别在于 SuM 专注于主体运动轨迹本身。
Camera Motion 相机运动
基于光流分析识别并评估视频帧间的运动类型是否与相机指令匹配。
Style Transfer 风格迁移
计算与风格文本对应的参考风格图像与生成视频帧之间的 DINO 特征相似度,量化风格迁移准确率。
此外还沿用 VBench 的通用视频质量指标(SC、BC、CLIP、FVD、TC、MS、AES 等)。
6实验 (Experiment)
6.1 基线方法
开源方法:TokenFlow、InsV2V、StableV2V、InsViE、AnyV2V、Omni-Video、LucyEdit
闭源商业模型:Runway Gen-4、Luma Ray3
另外在 EditVerse-Bench 上进行泛化性评估(详见补充材料)。
6.2 Goku-Bench 定量对比
指令任务 (Instruction Task)
| 模型 | 开源 | SC↑ | BC↑ | CLIP↑ | FVD↓ | TC↑ | MS↑ | AES↑ | ST↑ | SuM↑ | CM↑ | PR↑ | SR↑ | IF↑ | EQ↑ |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| TokenFlow | ✓ | 0.911 | 0.131 | 4539.82 | - | 0.899 | 0.94 | 0.42 | 0.514 | 0.426 | 0.457 | 0.34 | 0.63 | 0.44 | 0.32 |
| InsV2V | ✓ | 0.915 | 0.122 | 3988.01 | - | 0.951 | 0.96 | 0.56 | 0.485 | 0.533 | 0.542 | 0.358 | 0.284 | 0.391 | 0.317 |
| StableV2V | ✓ | 0.938 | 0.257 | 3129.58 | - | 0.921 | 0.97 | 0.45 | 0.642 | 0.545 | 0.631 | 0.297 | 0.331 | 0.375 | 0.304 |
| InsViE | ✓ | 0.929 | 0.379 | 2314.89 | - | 0.953 | 1.08 | 0.47 | 0.535 | 0.438 | 0.597 | 0.382 | 0.273 | 0.349 | 0.361 |
| AnyV2V | ✓ | 0.922 | 0.243 | 2876.93 | - | 0.915 | 0.93 | 0.39 | 0.598 | 0.598 | 0.494 | 0.312 | 0.366 | 0.259 | 0.388 |
| Omni-Video | ✓ | 0.966 | 0.369 | 1032.08 | - | 0.947 | 1.03 | 0.43 | 0.614 | 0.597 | 0.481 | 0.58 | 0.631 | 0.51 | 0.59 |
| LucyEdit | ✓ | 0.926 | 0.361 | 1420.36 | - | 0.954 | 0.95 | 0.51 | 0.694 | 0.598 | 0.637 | 0.476 | 0.755 | 0.549 | 0.579 |
| Ours (Goku-Edit) | ✓ | 0.969 | 0.432 | 993.93 | - | 0.955 | 1.15 | 0.59 | 0.955 | 0.633 | 0.927 | 0.738 | 0.832 | 0.627 | 0.645 |
| Runway (闭源) | ✗ | 0.958 | 0.472 | 1038.52 | - | 0.947 | 1.33 | 0.65 | 0.968 | 0.614 | 0.891 | 0.705 | 0.793 | 0.758 | 0.782 |
| Luma (闭源) | ✗ | 0.951 | 0.461 | 1095.64 | - | 0.940 | 1.29 | 0.63 | 0.957 | 0.601 | 0.872 | 0.681 | 0.769 | 0.741 | 0.761 |
参考图 + 指令任务
| 模型 | 开源 | ID一致↑ | SC↑ | BC↑ | CLIP↑ | FVD↓ | TC↑ | MS↑ | AES↑ | PR↑ | SR↑ | IF↑ | EQ↑ |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| StableV2V | ✓ | 0.41 | 0.931 | 0.382 | 2401.55 | - | 0.948 | 1.06 | 0.45 | 0.491 | 0.762 | 0.558 | 0.583 |
| AnyV2V | ✓ | 0.45 | 0.925 | 0.255 | 2750.11 | - | 0.919 | 0.94 | 0.41 | 0.533 | 0.78 | 0.572 | 0.591 |
| Ours (Goku-Edit) | ✓ | 0.54 | 0.968 | 0.417 | 925.55 | - | 0.958 | 1.17 | 0.52 | 0.718 | 0.832 | 0.851 | 0.824 |
| Runway | ✗ | 0.58 | 0.954 | 0.465 | 1028.73 | - | 0.948 | 1.32 | 0.63 | 0.691 | 0.802 | 0.872 | 0.848 |
| Luma | ✗ | 0.55 | 0.947 | 0.453 | 1081.29 | - | 0.943 | 1.28 | 0.61 | 0.668 | 0.785 | 0.858 | 0.831 |
- Goku-Edit 在绝大多数评测指标上取得开源最佳成绩,尤其在任务相关指标(SuM、CM、ST)上大幅领先。
- 在 PR、SR、CM、SuM 等物理与空间指标上,Goku-Edit 甚至超越商业闭源模型 Runway 与 Luma,验证了作者的结构化任务定义与专用数据构造。
- 虽然在 CLIP、MS、AES 等感知质量指标上略逊于商业模型,但 FVD、BC、TC 优势说明渐进式过滤系统有效抑制了时序伪影并保留了背景一致性。
6.3 定性评估

- 结构化编辑:给出"相机右移"指令,InsV2V、InsViE、Omni-Video、LucyEdit 均无法产生有效相机运动;Goku-Edit 正确执行 pan 操作并合理修补新暴露区域。
"移除双马尾女孩头顶红帽"这一复杂场景中,各基线均无法准确定位目标区域并对周围内容造成不同程度损伤,Goku-Edit 精确定位并完整移除,同时保持背景完整。 - 复杂多任务编辑:面对"给狗加黄棒球帽 + 视频转 Disney 风格"的复合指令,各基线均难以同时完成两项编辑;LucyEdit 虽加了帽子但风格化较差且损坏背景;Goku-Edit 精准完成全部指令并保持整体质量。
- 参考图编辑:基线方法普遍存在目标定位不准与参考图一致性差的问题;Goku-Edit 精确识别放置位置并保持与参考外观的高度一致,明显优于所有对比方法。
6.4 消融研究 (Ablation Studies)
训练数据消融(多任务编辑)
| 数据集 | 样本数 | CLIP↑ | FVD↓ | TC↑ | IF↑ | EQ↑ |
|---|---|---|---|---|---|---|
| InsV2V | 50k | 0.3421 | 3102.15 | 0.891 | 0.298 | 0.241 |
| InsViE | 50k | 0.3398 | 2843.67 | 0.873 | 0.301 | 0.253 |
| Señorita | 50k | 0.3502 | 2761.44 | 0.868 | 0.289 | 0.278 |
| Ours (未过滤) | 50k | 0.3541 | 2512.08 | 0.862 | 0.318 | 0.331 |
| Ours (过滤后) | 50k | 0.3780 | 1380.45 | 0.881 | 0.501 | 0.522 |
| Ours (过滤后) | 100k | 0.3891 | 1241.33 | 0.893 | 0.519 | 0.538 |
未过滤的 Goku 已超越所有已有数据集,说明任务覆盖扩展本身即带来实质收益;应用渐进式过滤后 IF 与 EQ 大幅提升;扩展至 100k 样本仍持续改善,表明性能尚未饱和。
Goku-Edit 核心组件消融
| MLLM | Dual-Branch | RoPE 对齐 | SpatialCFG | PR↑ | SR↑ | IF↑ | EQ↑ |
|---|---|---|---|---|---|---|---|
| - | - | - | - | 0.651 | 0.743 | 0.541 | 0.578 |
| ✓ | - | - | - | 0.664 | 0.756 | 0.573 | 0.591 |
| ✓ | ✓ | - | - | 0.695 | 0.789 | 0.588 | 0.612 |
| ✓ | ✓ | ✓ | - | 0.718 | 0.819 | 0.608 | 0.631 |
| ✓ | ✓ | ✓ | ✓ | 0.738 | 0.832 | 0.627 | 0.645 |
- MLLM 文本编码器:IF 由 0.541 → 0.573,语义理解显著提升。
- 双分支架构:PR、SR 分别 +0.031/+0.033,验证结构控制与外观渲染解耦释放了主分支建模能力。
- RoPE 对齐:SR 由 0.789 → 0.819,跨分支位置对应对边界精度不可或缺。
- SpatialCFG:免训练带来 PR +0.020, IF +0.019,抑制编辑外溢并强化指令跟随。
空间下采样因子 n 的消融

n = 1:两分支解耦不足,服装光滑但缺乏纹理。n = 2 / 4:细节逐步恢复,n = 4 达到最佳——纹理完整、定位精确,作为默认配置。n = 8:结构信号退化,出现定位失败。
用户研究
| 方法 | IF↑ | VQ↑ | TC↑ |
|---|---|---|---|
| InsV2V | 3.30 | 3.10 | 3.18 |
| InsViE | 3.42 | 3.18 | 3.25 |
| Omni-Video | 3.75 | 3.82 | 3.90 |
| LucyEdit | 4.05 | 4.12 | 4.08 |
| Goku-Edit | 4.58 | 4.51 | 4.65 |
Goku-Edit 一致排名第一,尤其在保持非编辑区域与处理复杂运动指令方面优势显著。
7结论 (Conclusion)
本文围绕指令式视频编辑的核心瓶颈,提出:
- Goku 数据集——大规模、高保真、覆盖相机运动、主体运动、参考图编辑与多任务模式的综合数据集;
- 严谨的数据构造流水线——攻克现有数据集常见的静态内容、语义错配、视觉质量差等问题;
- Goku-Bench 基准——配备新型评测指标,实现在技术质量、语义对齐、时序连贯性上的稳健评估。
实证结果表明,基于 Goku 训练的模型在多个任务与指标上一致优于此前数据集与 SOTA 方法,成为指令式视频编辑领域的新标杆。
§关键概念速查表
子问题分解 (Sub-Problem Decomposition)
贯穿数据合成的核心思想——将复杂编辑(风格迁移、位置迁移、多任务)拆解为可控的独立子任务,由专家模型分别处理,再通过过滤系统防止误差累积。
解耦双分支 (Decoupled Dual-Branch)
掩码分支专责结构约束、主分支专责外观渲染,通过双向交叉注意力互相沟通,兼顾精确定位与细节生成。
RoPE Scaling 对齐
不改动频率基,仅将掩码分支位置索引乘以 n 映射至高分辨率坐标,消除跨分辨率宏观错位,保留局部性偏置。
SpatialCFG
推理期免训练策略,通过对比"耦合 / 解耦"预测显式放大跨分支空间约束,正交组合于文本 CFG。
渐进式过滤系统
三阶段(源视频→条件校验→合成后校验),最终过滤约 88% 样本,与 Gemini2.5-Pro 深度联动。
专家模型协作
Grounded-SAM2(掩码)、Flux(图像编辑/参考图/首帧风格化)、VACE(外观编辑基座)、Wan2.2(视频合成)、RecamMaster(相机运动)、Minimax-Remover(Add/Remove 对偶)。
§关键洞察与复现要点 (Reproducibility)
本节将论文分散的关键洞察与实现细节汇编成"可执行的复现指南"。标注 [明确] 的项目在原文/表格/图注中直接给出;标注 [推断] 的项目基于 Wan2.2/VACE 家族默认设置或来源模型的官方文档合理推断,复现前请再核对补充材料。
核心洞察 (Key Insights)
- 数据 > 架构:Table 3 的第一次消融就是把 Goku 数据换到 LucyEdit 的架构上训练——即使不改模型,仅靠 Goku 未过滤版就能超越 InsV2V/InsViE/Señorita。这说明本文的最大贡献是数据,而非模型。要复现最终 SOTA,第一步应该是先把数据管线吃透。
- 子问题分解 (Sub-Problem Decomposition) 是数据合成的元原则:凡是"直接一次性生成会崩"的任务(如整段视频风格迁移、视频级物体重定位、多任务叠加),一律拆成"图像级操作 + 时序传播"或"任务串行链"。这是 Goku 对比其他数据集能覆盖到结构化编辑的唯一原因。
- 对偶性 (Duality) 破解 Add:Add 直接生成会有漂浮/遮挡伪影;作者反过来先 Remove(Minimax-Remover 更成熟),再交换角色即得到高质量 Add——这是极简且极有效的一招。
- 过滤是数据管线的价值放大器:Table 3 中"Ours w/o"→"Ours"(同为 50k)IF 从 0.318→0.501(+58%),EQ 从 0.331→0.522(+58%)。过滤系统贡献了性能的一半以上;88% 的丢弃率是可以接受的代价。
- MLLM 是"文本编码器"而非"生成器":Qwen3VL-8B 只用于提取文本特征供 diffusion 消费,不参与生成,这与 Omni-Video 让 MLLM 直接生成视频的路线完全不同,成本更低但依然拿到了指令理解的收益。
- V2M 反向路径的必要性:如果只做 M2V(掩码引导视频),去噪推进过程中掩码会与视频状态脱节,导致边界闪烁。V2M 让掩码分支能"看到"当前视频状态,形成闭环。这是 dual-branch 之所以稳定的关键。
- SpatialCFG 是 CFG 的"空间维度扩展":标准 text CFG 放大文本条件,SpatialCFG 放大跨分支空间条件。两者正交组合——每个 sampling step 需要 4 次前向((cond, uncond) × (dual, indep)),推理成本约翻倍但换来 PR/IF 的一致性提升。
- 下采样因子 n=4 是精细度—约束强度的最优点:n=1 两分支坍缩;n=8 结构信号被稀释;n=4 是唯一能让掩码分支的 token 数刚好平衡的甜点。
4.1 数据管线复现关键参数
视频源与预处理
| 项 | 值 | 说明 / 来源 |
|---|---|---|
| 源视频库 | Koala-36M | [明确] 从中筛出 1M 高质量片段作为源 |
| 片段时长 | 3 - 10 s | [明确] 突出连贯动作与场景 |
| 分辨率 | ≥ 720p | [明确] 每段视频 65~129 帧 |
| 过滤组件 | — | 镜头切换检测 + 美学评分 + 运动动态分析 + OCR 水印移除 + Gemini2.5-Pro 内容丰富度筛查 |
| 指令生成 MLLM | Gemini 2.5-Pro | [明确] 数据管线中一切语义任务都用它;作者也提供 Qwen3VL-30B 的开源替代版 |
各任务专家模型
| 任务 | 专家模型 | 输入 → 输出 |
|---|---|---|
| Remove | Minimax-Remover | 源视频 + 时序掩码 → 移除后视频 |
| Add | —(对偶自 Remove) | 把 Remove 样本的 (in, out) 反转即可 |
| Swap / Alter | VACE | 源视频 + Grounded-SAM2 掩码 + Flux 参考图 → 编辑后视频 |
| Style Transfer | Flux → 深度提取 → VACE | 3 步:首帧风格化 → 逐帧深度图 → 深度序列 + 风格化首帧输入 VACE 传播 |
| Camera Movement | RecamMaster | 源视频 + 相机运动指令 → 新相机轨迹视频(20+ 模式;复杂运动分解为基础序列) |
| Subject Movement (action) | Wan2.2 | Gemini 生成两个动作描述 (walking→running),同 subject 独立合成两条视频 |
| Subject Movement (position) | Flux → Wan2.2 | Flux 在首帧移动物体 → Wan2.2 从新首帧扩展成连贯视频 |
| Reference Add / Swap | Flux 重绘参考图 → VACE | 关键:参考图必须做扰动(姿态/光照/背景),否则模型退化为像素复制 |
| Multi-Task Edit | 专家模型串行 | Gemini 分解为 2-5 个子任务,前一步输出 = 后一步输入,中间过 Tier-3 过滤 |
渐进式过滤系统三层
| 阶段 | 过滤器 | 阈值 / 判据 |
|---|---|---|
| Tier 1: 源视频 | Koala-36M → 1M | 综合美学 + 运动 + 切换 + OCR + Gemini 内容丰富度;具体阈值见补充材料 |
| Tier 2: 条件校验 | 掩码完整度 (IoU) | [明确] IoU 阈值过滤(论文未给具体数值——建议先用 IoU ≥ 0.7 起步) |
| Tier 2: 条件校验 | Gemini2.5-Pro | 校验(编辑目标 ↔ 指令)语义一致;参考图视觉合理性;任一不过则丢 |
| Tier 3: 合成后 | 低层视觉 | 帧间一致性 + 频域伪影检测 + 美学重打分 |
| Tier 3: 合成后 | 高层语义 (Gemini) | 编辑准确性 + 真实感;三维评分:instruction alignment、frame stability、photorealism |
| 整体丢弃率 | ~88% | [明确] 合成 100 例只保留约 12 例;因此为得到 200 万,实际合成量约 1670 万 |
4.2 Goku-Edit 模型复现关键参数
| 组件 | 配置 | 说明 |
|---|---|---|
| 主分支基座 | Wan2.2-5B | [明确] 视频扩散主干,两分支共享同一预训练权重后独立微调 |
| 掩码分支基座 | Wan2.2-5B | [明确] 结构相同但输入通道不同(M vs Ve) |
| 文本编码器 | Qwen3VL-8B (frozen) | [明确] MLLM 冻结,仅 diffusion 分支训练 |
| Latent 编码器 | 预训练 VAE | [明确] 用于 Ir, Vs, Ve, Vd, M;Wan2.2 官方 3D VAE |
| 空间下采样因子 n | n = 4 | [明确] 消融最佳;n=1 纹理糊,n=8 定位失败 |
| 条件拼接维度 | 时间维 [zr, zs, ze,t]T | [明确] 沿 T 拼接而非 C,重用 Wan 的时空注意力 |
| M2V / V2M 交叉注意力 | 每 Wan Attention Block 后串接 | [明确] 见 Fig 3;两个方向都做 |
| RoPE Scaling 因子 | × n = × 4 | [明确] 掩码分支位置索引乘 n;不改频率基 |
SpatialCFG 推理配置
| 系数 | 作用 | 建议值 |
|---|---|---|
| se | video 分支跨分支增量放大——抑制编辑外溢 | [推断] 在 3~5 之间搜索(论文未给具体值,参考 Wan/CFG 家族常用值) |
| sm | mask 分支跨分支增量放大——细化边界 | [推断] 3~5 |
| stext | 标准文本 CFG | [推断] Wan2.2 官方默认 5.0~7.5 |
| 每步前向次数 | 4 | = 2 (dual/indep) × 2 (cond/uncond),是标准 CFG 的 2× |
训练配置(消融实验)
| 项 | 值 | 来源 |
|---|---|---|
| 训练样本量 | 50k / 100k | [明确] Table 3 数据消融 |
| 训练步数 | 6k steps | [明确] Table 3 备注 |
| Batch / LR / Optimizer | — | [未给] 论文正文与消融表均未列出;建议参考 Wan2.2-5B 微调默认值(batch 效应等价 >=64、LR 1e-5、AdamW) |
| 训练硬件 | — | [未给] 5B × 双分支 + Wan 3D 注意力,建议至少 8×A100/H100 |
4.3 训练 & 推理伪代码
训练主循环(PyTorch 风格)
# 每次训练迭代 def training_step(batch): # 1. 编码所有条件与目标 z_r = vae.encode(batch.ref_image) # 参考图 z_s = vae.encode(batch.src_video) # 源视频 z_e = vae.encode(batch.edit_video) # GT 编辑视频 z_d = vae.encode(downsample(batch.src_video, n=4)) # 1/n 分辨率源 z_m = vae.encode(batch.mask_video) # GT 编辑区域掩码 T_p = mllm_encoder.encode(batch.instruction) # frozen Qwen3VL-8B # 2. 加噪 t = sample_timestep() z_e_t = q_sample(z_e, t); z_m_t = q_sample(z_m, t) # 3. 组装分支输入 (公式 1) z_e_prime = concat([z_r, z_s, z_e_t], dim=T) z_m_prime = concat([z_d, z_m_t], dim=T) # 4. 双分支联合前向 (含 M2V + V2M 交叉注意力) for block in zip(video_branch.blocks, mask_branch.blocks): h_e = video_block.self_attn(h_e, T_p) h_m = mask_block.self_attn(h_m, T_p) # RoPE Scaling: 掩码 token 位置索引 × n pos_m_scaled = mask_positions * n # M2V: 视频 Q ← 掩码 KV h_e = h_e + cross_attn(Q=h_e, KV=h_m, Q_pos=video_positions, KV_pos=pos_m_scaled) # V2M: 掩码 Q ← 视频 KV (闭环,防边界飘) h_m = h_m + cross_attn(Q=h_m, KV=h_e, Q_pos=pos_m_scaled, KV_pos=video_positions) eps_e_pred = video_branch.head(h_e) eps_m_pred = mask_branch.head(h_m) # 5. 双分支加权 diffusion 损失 loss = mse(eps_e_pred, gt_noise_e) + λ * mse(eps_m_pred, gt_noise_m) loss.backward()
SpatialCFG 推理(每 sampling step 4 次前向)
def spatial_cfg_step(z_e_t, z_m_t, T_p, s_e, s_m, s_text): # 4 次前向:{dual, indep} × {cond, uncond} z_null_e = torch.zeros_like(z_e_t) z_null_m = torch.zeros_like(z_m_t) # A. 耦合预测 (M2V+V2M ON) — 有条件 eps_e_dual_c, eps_m_dual_c = model(z_e_t, z_m_t, T_p, cross=True) # B. 解耦基线 (video 分支 M2V OFF, 用 null mask) eps_e_indep_c, _ = model(z_e_t, z_null_m, T_p, cross=False) # C. 解耦基线 (mask 分支 V2M OFF, 用 null video) _, eps_m_indep_c = model(z_null_e, z_m_t, T_p, cross=False) # 空间增强 (公式 3) eps_e_c = eps_e_indep_c + s_e * (eps_e_dual_c - eps_e_indep_c) eps_m_c = eps_m_indep_c + s_m * (eps_m_dual_c - eps_m_indep_c) # 同上但 T_p = null → 无条件版本 eps_*_uc eps_e_uc, eps_m_uc = spatial_cfg_uncond(z_e_t, z_m_t, s_e, s_m) # 文本 CFG 正交叠加 (公式 4) eps_e_final = eps_e_uc + s_text * (eps_e_c - eps_e_uc) eps_m_final = eps_m_uc + s_text * (eps_m_c - eps_m_uc) return eps_e_final, eps_m_final
4.4 复现路径与常见坑
- 先复现数据管线:数据是最大贡献。可以先用小规模(1k 样本)验证 Add/Remove 对偶、风格迁移三步、Multi-Task 串行的每一步都能稳定输出,再上大规模。
- 过滤系统的实现细节需要对齐:Gemini2.5-Pro 的评分 prompt 是复现的核心不确定性来源。论文说 prompt 模板在补充材料——如果补充材料未开源,一个可行的替代是使用作者提供的 Qwen3VL-30B 版本。
- 双分支的 batch 内存倍增:两条 Wan2.2-5B 分支同步训练,激活约 2×,加上 M2V+V2M 交叉注意力(QKV 双向)内存再涨。若显存吃紧,可以先冻结 mask 分支只训 video 分支,或使用 gradient checkpointing。
- RoPE Scaling 只影响位置编码,不改前向结构:直接在 rotary embedding 计算前把 mask 分支的 (x,y) 索引乘 n 即可,无需重训 base frequency。
- SpatialCFG 推理开销:4 次前向使推理时间约翻倍。可以在早期步启用、后期步只用标准 CFG 以省时。
- 参考图扰动(Ref Swap/Add)不可省:直接用原视频裁剪的参考图会让模型学会"pixel copy",Reference Add/Swap 泛化会崩。
- Multi-Task 中的任务顺序:论文未强调顺序,但实践中"先结构后外观"通常更稳(如先 Camera Move → 再 Style,反过来风格特征会被相机运动破坏)。
§Q&A:读者常问的关键问题
Q1:Goku 相较 Ditto、Señorita-2M、OpenVE-3M 的核心差别究竟是什么?规模?
不是规模。OpenVE-3M 有 300 万数据,比 Goku 多 50%。真正的差别是任务空间:
- Ditto/Señorita/InsViE/OpenVE:全部只做基础外观编辑(Add/Remove/Swap/Alter/Style),本质仍在"改像素"。
- Goku 首次在大规模配对数据层面覆盖:Camera Movement(相机内外参变化)、Subject Movement(主体运动/位置改变)、Multi-Task(2-5 步组合)、Reference-based(参考图引导)。
因此,即便对方数据更多,若下游任务是复杂结构编辑,模型仍无从学起。这是为什么 Table 3 中同一架构下,Goku(未过滤)就已胜出。
Q2:为什么非要用 MLLM (Qwen3VL-8B) 做文本编码器?CLIP-T5 不够吗?
标准 CLIP text encoder(77 tokens 上限、纯文本对齐)在处理 "remove the red hat on the girl with twin pigtails" 这类指代密集指令时会丢失关系信息。MLLM 的优势:
- 更长的上下文窗口,多任务复合指令不需要截断。
- 训练自视觉+语言联合语料,天然携带"世界物理常识"(例如"给狗戴帽"隐含"帽在头顶")。
- 对多子句、指代消解、否定句更鲁棒。
Table 4 消融显示替换为 MLLM 后 IF 从 0.541 → 0.573(+3.2 pt),提升不大,但为后续组件奠基——如果没有对复杂指令的正确理解,双分支和 SpatialCFG 也无从发挥。
Q3:为什么要设计一个掩码预测分支?直接把 GT 掩码当条件塞给 video 分支不行吗?
可以,但推理期你没有 GT 掩码。用户只给指令与源视频,模型必须自己确定"改哪里"。三种可选方案:
- 方案 A:外接一个掩码预测器(如 SAM)→ 送给 video 分支。缺点:两阶段串行,掩码错就全错,且 SAM 不理解编辑指令。
- 方案 B:让 video 分支端到端隐式学空间定位。缺点:主分支既要做外观又要定位,容量被稀释,PR/SR 差。
- 方案 C(Goku-Edit):显式并行掩码分支,与 video 分支同步去噪并双向交流。这样每一步的掩码预测都能利用 video 分支的当前状态,反过来 video 分支也拿到最新的空间引导。
Table 4 显示 dual-branch 使 SR 从 0.756 → 0.789(+3.3 pt),PR 从 0.664 → 0.695,就是空间约束的直接收益。
Q4:RoPE Scaling 在数学上到底做了什么?为什么不能直接双线性上采样掩码?
如果对掩码 latent 直接双线性上采样到高分辨率再做 attention,会引入插值噪声并把 token 数放大 n² 倍——计算成本×n²=×16。RoPE Scaling 是让计算便宜、位置对齐正确的取巧方案:
- 掩码分支仍然只有 (H/n)×(W/n) 个 token,计算成本不变。
- 但计算 rotary embedding 时,用的位置索引是 (nx, ny) 而非 (x, y)。
- 结果:video 分支位于 (nx+δ, ny+δ) 的 query 与掩码位于 (nx, ny) 的 key 计算相对位置时,得到 (δ, δ)——这正是它们真实的物理相对距离。
本质是把"低分辨率 token"当作"高分辨率栅格上的采样点"来做位置计算,位置正确、算力不增。
Q5:SpatialCFG 与 Text CFG 的关系?能不能只用一个?
它们放大的是不同来源的信号,是正交的:
- Text CFG:ε(cond) - ε(uncond),放大文本条件的贡献。
- SpatialCFG:ε(dual) - ε(indep),放大跨分支交叉注意力的贡献。
只用 Text CFG,模型仍会执行编辑,但边界飘、区域外泄;只用 SpatialCFG 而无 Text CFG,模型对指令的敏感度会下降。因此论文用 4 次前向做联合放大:{cond, uncond} × {dual, indep}。这是推理开销的主要来源。
如果显存/延迟受限,可以先只做 Text CFG,最后 20% 步启用 SpatialCFG——工程折中。
Q6:为什么过滤掉 88% 的合成样本仍然是划算的?
因为 合成成本 ≪ 训练成本 ≪ 反复 debug 成本。留下的每一个样本都要在训练中被反复 forward/backward 数十次,坏样本产生的错误梯度会污染整个模型。
Table 3 直接给出证据:同为 50k 样本,过滤前后 IF 差 +58%,EQ 差 +58%。也就是说,过滤后的 12k 有效样本比未过滤的 50k 还好得多——在数据合成阶段"多丢一点"是正确策略。
Q7:Goku 的多任务编辑(Multi-Task Edit)用专家模型串行合成,不会累积误差吗?
会,但作者用两招缓解:
- 任务规划器 (Gemini2.5-Pro) 负责识别兼容的任务组合、避免冲突(如"移除狗 + 给狗戴帽"这种矛盾指令)。
- Tier-3 过滤直接把最终结果扔给 Gemini 判语义与视觉合理性。累积误差过大的样本会在这一层被剔除。
因此该方法接受"高失败率"作为代价,用过滤把误差控在 12% 以下。
Q8:训练用多少数据 / 多少步?论文的数值意义?
论文正文只在消融实验中给出训练量:
- Table 3 消融:50k / 100k 样本,6k steps,架构固定为 LucyEdit。
- 最终 Goku-Edit 主结果(Table 2)用了多少样本、多少步、多少 GPU 时——正文未列出。
Table 3 的"100k 未饱和"暗示最终模型可能用到了几十万到全部 200 万样本。这是复现的最大空白点,需要作者在补充材料/开源 repo 中补齐。
Q9:为什么在 CLIP/MS/AES 上逊于 Runway/Luma?是模型不够好吗?
不是。作者的解释与之相符:
- Runway/Luma 是闭源商业模型,训练算力和数据规模远超本文——它们的视觉美学先验(AES)自然更强。
- 但 Goku-Edit 在 PR/SR/CM/SuM 这类结构与物理指标上超越了商业模型,说明结构化任务定义 + 数据构造带来的收益是正交于视觉美学的。
- 换言之:作者选择在有限算力下把资源放到"结构正确",而非"更好看"——这是数据集论文的合理定位。
Q10:如果我要基于这篇工作发下一篇,最容易切入的空缺是什么?
见下一节"局限与改进方向"。摘要三个最有前景的方向:
- 时间维度:Goku 只处理 3-10 秒短片,长视频(分钟级)编辑仍未解决。
- 音频/多模态:Goku 不涉及音频编辑;音-视协同编辑是自然扩展(作者的 SpongeBob 工作已在此方向)。
- 交互式编辑:Goku 假设一次性下达完整指令;用户逐步细化的多轮交互场景值得研究。
§局限性与改进方向
基于对论文的独立审视,本节列出论文未主动强调、但对复现或后续研究有影响的问题。红色卡片指出局限,绿色卡片给出可行的改进方向。
数据层面局限
全部来自 Koala-36M
整个 Goku 数据集起源于同一个源库 Koala-36M。分布偏好、拍摄美学、内容主题都会被继承。跨域泛化(如医疗、卫星、动漫)尚未验证。
片段仅 3-10 秒 (65-129 帧)
更长的电影级编辑(1-5 分钟)需要处理镜头切换、故事一致性、更长时序连贯——这在 Goku 数据分布中缺席。
数据管线深度绑定 Gemini2.5-Pro
过滤评估、任务规划、语义验证均依赖 Google 闭源模型。对可复现性与商用授权有硬约束。作者虽提供 Qwen3VL-30B 替代,但性能对齐未量化。
纯视觉编辑
视频作为多模态媒介,音频编辑(音效替换、语音变声、音画同步)是重要缺口。真实创作场景多需音-视协同。
专家模型的失败模式会被继承
Goku 依赖 VACE、Wan2.2、Flux 等作为"教师"。任何一个专家模型有偏差(如 Flux 在特定光照下崩),都会被继承进 Goku——过滤只能剔除严重错误,微妙偏差会隐性累积。
模型层面局限
训练/推理均双倍
双分支 Wan2.2-5B 使显存/算力翻倍,SpatialCFG 使推理再翻倍。相较 LucyEdit 单分支路线成本高得多,商业化时是硬伤。
MLLM 的长指令行为未消融
论文用 Qwen3VL-8B 只做定长文本编码,未给出对超长复合指令(如 5 步以上)的行为曲线。
se, sm, stext 数值缺失
SpatialCFG 的收益依赖三个 hyperparameter 的组合,但正文未提供最优取值也未提供搜索区间。复现者需要自己 sweep。
只展示 cherry-picked 定性结果
Fig. 6 都是成功案例,缺少"Goku-Edit 也会崩"的情形展示。这在数据集/模型论文中并不罕见但不利于社区理解方法边界。
基准层面局限
4 个通用编辑指标由 Gemini 打分
PR/SR/IF/EQ 都由 Gemini2.5-Pro 判断。这带来自我循环风险:训练用 Gemini 过滤的数据、评测又让 Gemini 打分,如果 Gemini 有系统偏差,Goku 家族在此偏差上会有"结构性优势",未必反映真实感官。
30 位参与者,无 Krippendorff α
Table 5 未报告标注者一致性、置信区间或统计显著性检验。5 分 Likert 上的 4.58 vs 4.05 差距是否显著,不能只看点估计。
Goku-Bench 也来自 Koala-36M
训练集与测试集共享上游视频源,对分布外泛化的评估不足。这不是数据泄漏(clip 级别不重叠),但美学/场景先验高度重合。
Goku-Bench + EditVerse-Bench
缺少在其他社区常用 IVE bench(如 TGVE-Bench)上的横向数据,不便与更早工作的历史结果对齐。
后续研究可行方向
时空级联 + memory
沿用子问题分解思想:将 1 分钟视频切成 10 秒段,段间用记忆机制(如 KV-cache 或 latent memory)保持一致性;每段用 Goku-Edit,段间训练一个"衔接分支"处理边界闪烁。
Audio-Visual Goku
接入音频专家(AudioLDM、MusicGen)作为管线的第 6 类专家,同时构造"改视觉→自动同步改音频"的 Multi-Modal-Edit 类别。作者已有 SpongeBob(音-视同步生成)工作,可无缝集成。
多 judge 集成 + 人工校准
用 Gemini + Qwen3VL + GPT-4o 三个 MLLM 集成打分,取中位数。同时在 Goku-Bench 上做MLLM ↔ 人的 Pearson 相关分析,公开 residual,让社区判断可信度。
降低推理成本
把 Goku-Edit 的双分支 + SpatialCFG 推理结果作为"教师",蒸馏一个只有单分支的 student——保留 90% 性能,推理成本降回 LucyEdit 级别。
Chat-based Video Editor
用户逐步下达"再红一点"、"帽子往左偏"这类增量指令,模型在保持前一轮编辑的基础上做局部精修。需构造"编辑轨迹"数据(V0 → V1 → V2)和轨迹级损失。
结合 4D 场景理解
Camera / Subject Movement 目前仍在 2D 图像层面操作。若接入 3D 场景重建(Gaussian Splatting、NeRF),可实现严格几何一致的相机运动与主体重定位——目前的物理规则保真度(PR)还有很大提升空间。
模型-数据飞轮
Goku-Edit 训练完成后,本身即是一个"编辑专家",可以反过来作为数据管线的第 7 号专家生成新的 Multi-Task 数据,形成"模型 → 数据 → 更好模型"的飞轮。作者已经暗示"100k 未饱和",飞轮有实际收益。
从"指令→编辑"到"意图→编辑"
用户不总是能精确描述想要什么。可以引入"意图澄清"模块:用户给一句模糊指令,MLLM 反问或建议 3 个候选编辑,人选后再执行。这偏向 HCI 层面但对产品化极为关键。