§摘要 (Abstract)
本文提出 Qwen-Image-2.0-RL——一套后训练(post-training)管线,通过 基于人类反馈的强化学习 (RLHF) 与 在策略蒸馏 (On-Policy Distillation, OPD) 同时提升 Qwen-Image-2.0 扩散模型在视觉质量与指令遵循两方面的能力。 为提供可靠的奖励信号,作者通过对视觉-语言模型 (VLM) 进行 pointwise 打分 + 链式思维 (CoT) 推理 的微调,构建了任务专用的复合奖励模型:文生图 (T2I) 覆盖对齐 / 美学 / 人像三个维度, 图像编辑覆盖指令遵循准确性 / 人脸 ID 保持两个维度。 在此奖励系统之上,作者搭建了可扩展的 GRPO 强化学习框架,引入 hybrid CFG 策略以保留预训练知识、 基于组内奖励极差的 prompt 筛选以及分类别奖励权重校准。 为将 T2I 与编辑两个任务专用的 RL 策略融合成单一模型,作者提出在策略蒸馏作为最终训练阶段: 通过轨迹级速度场匹配把多个教师合并成一个学生模型。 最终 Qwen-Image-2.0-RL 在 Qwen-Image-Bench 上得到 57.84 的综合分数(较基线 +2.61), 在 T2I 竞技场获得 1193 Elo 评分(+78),在图像编辑竞技场获得 1349 Elo(+93), 在美学质量、指令遵循和编辑准确性上均取得一致提升。
1引言 (Introduction)
扩散与流匹配生成模型(Sohl-Dickstein 2015、Ho 2020、Song 2021)已在高保真图像生成上取得显著成功。 从早期潜在扩散 (Rombach 2022) 发展到 Transformer 驱动的可扩展架构 (Peebles & Xie 2023; Chen 2024; Esser 2024),最新系统进一步引入 视觉语言基础模型作为条件编码器(BlackForest 2024、Wu 2025a、Cai 2025), 以更强的语义 grounding 与多模态世界知识实现更精细的指令遵循与图文对齐。 与此同时,商业系统(GPT Image、Nano Banana、Seedream)已在生成质量上迈过又一个门槛, 统一架构进一步把生成能力扩展到编辑任务,让单个模型服务于生成与编辑两条赛道。
1.1 三个待解决的挑战
尽管预训练效果亮眼,作者指出监督训练下的扩散模型输出与人类审美之间仍存在持续存在的 gap: 去噪得分匹配 (denoising score matching) 目标并不直接刻画构图协调、纹理细腻、prompt 忠实性、风格一致性等偏好维度。 RLHF 是弥合这一鸿沟的原则性方法,但把它扩展到扩散模型面临三个新问题:
- 可靠的奖励信号必须跨任务捕捉多维质量——T2I 需要全局美学与 prompt 遵循, 编辑需要细粒度身份保持,因此需要组合式、任务感知的奖励设计。
- 现有扩散 RL 框架多在 LoRA 微调场景下验证(Flow-GRPO、DiffusionNFT), 真实场景下的多奖励、多任务、全参数训练仍未被充分探索。
- 部署要求把任务专用策略合并成单一模型而不牺牲每一任务的质量。
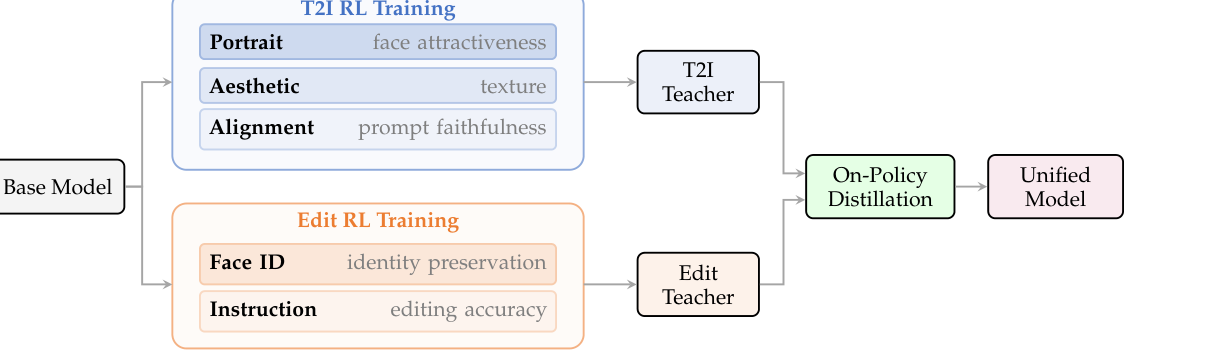
1.2 本文的三项贡献
VLM 复合奖励模型
基于 Qwen 系列 VLM 微调,采用 pointwise + CoT 打分范式(作者实证发现优于 pairwise), T2I 用对齐 / 美学 / 人像分层奖励,编辑用指令遵循 + 人脸 ID 一致性组合奖励。
可扩展 RL 训练框架
基于 GRPO 的多奖励优势估计,引入 hybrid CFG(rollout 用 CFG,训练目标不用), 基于组内奖励极差的 prompt 过滤,以及分类别奖励权重校准。
在策略蒸馏 (OPD)
把 T2I 与编辑两个 RL 教师通过轨迹级速度场匹配合并到一个学生里, 规避跨任务优化冲突,同时消除部署时对奖励模型的依赖。
1.3 主要结果一览
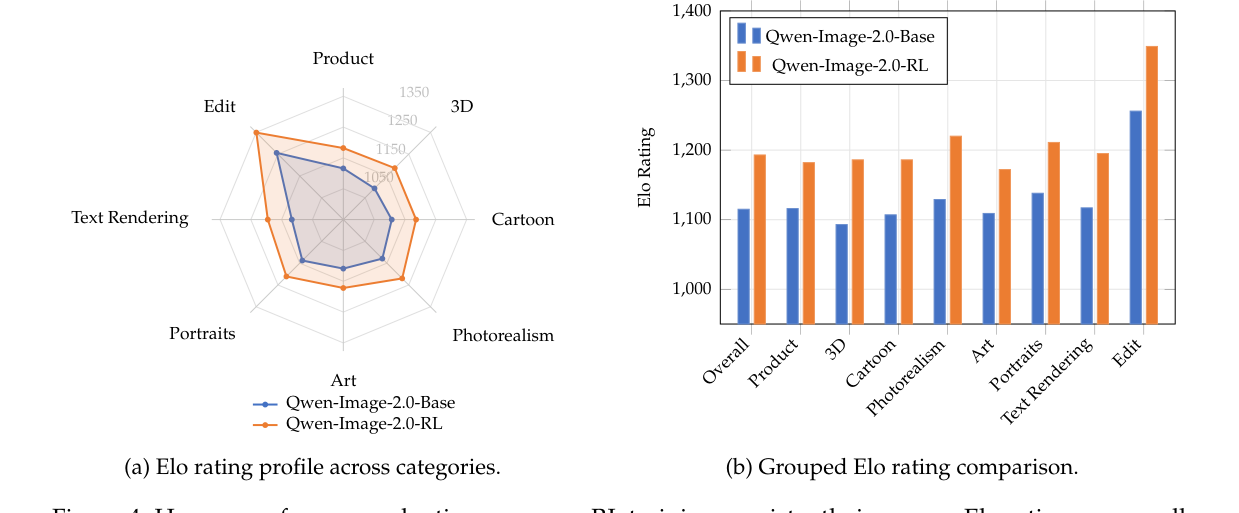
- Qwen-Image-Bench 综合分:55.23 → 57.84 (+2.61),其中 Creative Generation +6.72、Real-world Fidelity +4.29;
- T2I 竞技场 Elo:1115 → 1193 (+78),最大增益出现在 3D Modeling (+93) 与 Photorealism (+91);
- 图像编辑竞技场 Elo:1256 → 1349 (+93),验证编辑侧 RL 训练同样有效。
2背景 (Backgrounds)
2.1 Flow Matching 扩散模型
Flow Matching 框架 (Lipman 2022; Liu 2022) 定义前向路径为线性插值:
对时间求导得到条件速度场 v := ε − x0;训练一个网络 vθ(xt, t, c) 通过 flow matching 目标去逼近它:
推理时反向解概率流 ODE:dxt/dt = vθ(xt, t, c),从 t=1 到 t=0。
2.2 面向扩散模型的强化学习
Flow-GRPO:把去噪当 MDP
Flow-GRPO (Liu 2026a) 将 GRPO 从 LLM 扩展到 flow matching:给定 prompt c,
策略 πθ 生成 G 张图像,奖励模型打分后计算组归一化优势:
由于 flow matching 使用确定性 ODE生成,直接套 GRPO 会出问题;Flow-GRPO 把它改成等价的随机采样器:
Euler-Maruyama 离散化后转移密度是高斯,可解析计算重要性采样比 rt(i)(θ)。策略优化用带裁剪的代理目标:
DiffusionNFT:用前向过程做优化
DiffusionNFT (Zheng 2025) 换了一种思路——在前向 xt = (1−t)x0 + tε 上做优化,构造正/负速度:
训练目标为 advantage 加权的 velocity MSE:
其中 r = clip(A, ±Amax) / (2Amax) + 0.5 ∈ [0,1];再加一个 KL penalty 抑制策略偏离预训练参考。
本文选择:作者在 GRPO 骨架上做了三处适配,均在 §4 中详细展开—— hybrid CFG、异步奖励管线、多奖励 group-normalized advantage。
3奖励建模 (Reward Modeling)
3.1 奖励模型训练范式:pointwise vs pairwise
作者对比了两种 VLM 奖励模型训练范式:
成对偏好排序
用 Bradley-Terry 排序损失:Lpair = − Σ log σ(R(xw) − R(xl))。
标注协议按图文一致性 > 结构失真 > 纹理质量 > 美学吸引力的严格优先级。
逐图绝对打分
MSE 到人工标注的 Likert 5 分:Lpoint = Σ (R(x, c) − y)2;
RM 通过输出 tokens ∈ {1,2,3,4,5} 的概率期望得到分数:
R(x, c) = Σs s·pφ(s | x, c)。
Pointwise 标注沿两个维度分别打分:
- Quality:清晰度、光照、色彩平衡、风格一致性、材质纹理;
- Fidelity:结构正确性、物理一致性、AI 伪影(不自然的平滑或纹理重复)。

3.2 T2I 生成的分层奖励
作者的 T2I 奖励设计遵循分层递进的逻辑:先保证 prompt 忠实,再叠加美学,最后针对人像专门优化。
图文对齐奖励
按优先级评估:(1) 物体存在与数量,(2) 属性正确性(颜色/大小/形状/材质), (3) 空间关系,(4) 动作与姿势。违反最高优先级的图,无论其他维度都被封顶低分。
美学奖励
在 prompt 忠实基础上叠加视觉质量:构图平衡、光照真实、纹理保真、艺术连贯性。 使用 §3.1 的 pointwise 数据集训练。
人像奖励
专门解决通用美学不够的问题:面部比例、身份保留细节、皮肤/头发纹理真实感。 显式检查常见故障——手指数错误、面部畸变、身体比例失衡。用高质量人像参考图数据集单独训练。
3.3 图像编辑的奖励模型
把 pointwise 范式迁移到编辑任务,同时增加一个专用模型解决 VLM 力不能及的细粒度身份保持:
指令遵循奖励
输入是 (源图, 编辑指令, 输出图) 三元组;VLM 先把指令拆解为核心编辑要求 + 非核心辅助要求, 然后按结构化 rubric 打分:(1) 核心指令是否被完成,(2) 非核心要求是否被满足,(3) 输出整体是否视觉连贯。
人脸 ID 一致性奖励
作者发现纯 VLM 视觉一致性 reward 无法可靠捕捉细微的面部身份漂移,因此引入一个专用 model-based 打分器 ——它在 embedding 层给出精确的身份保留信号,与 VLM 的高层语义一致性形成互补。
4训练 (Training)
4.1 共享训练管线
4.1.1 Hybrid CFG 策略
训练中「rollout 采样时是否加 CFG」「策略优化目标里是否包含 CFG」是两个独立的开关。作者系统对比了三种设置:
rollout + 训练均加 CFG
训练不稳定,图像逐渐劣化直至彻底崩塌为不连贯输出。
两阶段均无 CFG
reward 分数在涨,但模型渐渐丢失风格化能力和世界知识——名人相貌复现不了、风格化生成能力退化。 原因:预训练模型高度依赖 CFG 来完整表达其学到的知识。
仅 rollout 阶段加 CFG
rollout 用 CFG 得到高质量候选以获得可靠奖励;策略优化目标里剔除 unconditional 分支—— 既维持训练稳定性,又大幅降低算力开销。

4.1.2 异步奖励管线
奖励模型作为独立的远程 API 服务部署,与训练进程分离。同步调用会被网络 I/O 拖慢,因此:
- 策略在 GPU 上生成一批图像并跨 rank gather;
- 后台线程异步把图像提交到远程 RM 端点;
- 响应回来后 rank 间同步 gather 原始分数、按 prompt 组归一化、算 advantage、更新策略。
这个设计把奖励延迟几乎完全隐藏在 inference 计算之后,让训练时间不随奖励模型数量线性增长。
4.1.3 多奖励优势估计
组归一化对每个 RM 单独做,然后加权求和(灵感来自 Liu 2026b, GDPO):
关键点:逐 prompt-group 归一化让复合奖励对各 RM 的绝对量纲差异保持不变—— 避免任何一个 reward 因数值范围大而支配整体 advantage 信号。
4.2 任务特定优化
时间步子采样
rollout 用 40 步 ODE solver。若在所有 40 步都算 RL loss 会快速 reward hacking。 作者只在 rollout 时间步的子集上训练,重点覆盖 t 靠近 1 的高噪声时间步—— 它们主宰全局结构与语义布局,是策略优化更 robust 的目标。
Prompt 过滤
基线模型对每个候选 prompt 做 G 次 rollout,计算复合奖励; 只保留组内 reward 极差 (max − min) 大于阈值的 prompt—— 过高或过低的 prompt 提供的策略优化信号弱。此步显著提升训练效率。
分类别奖励权重
把 prompt 按语义类别(人像、风景、字体、通用...)划分,每类分配不同的奖励权重向量—— 比如人像 prompt 提高 portrait reward 权重,字体 prompt 提高对齐 reward 权重。 避免 RL 收敛到单一主导风格。
4.3 在策略蒸馏 (On-Policy Distillation, OPD)
直接问题:单独训完的 T2I 模型编辑能力退化,反之亦然。OPD 的核心思想: 把两个任务专用教师 通过学生自身轨迹上的速度场匹配 蒸馏到单一学生里。
4.3.1 训练目标
学生 vθ 从预训练 base 初始化,用 N 步离散反向 ODE 从 t=1 解到 t≈0,
保存整条轨迹 {xt0, xt1, ..., xtN},
然后让学生在自己的轨迹上匹配任务对应的教师速度:
「学生学习纠正自己在自己推理轨迹上的预测误差」——这是 OPD 有别于普通蒸馏的关键。
4.3.2 多教师蒸馏机制
- 维护两个教师:T2I 教师(对齐+美学+人像)和 编辑教师(指令+人脸 ID);
- 每个 batch 根据 sample 的任务类型动态选中对应教师;
- 为控 GPU 显存,只有激活教师加载到 GPU,非激活教师 offload 到 CPU;
- 教师原本用 CFG 训练——OPD 里教师速度预测加 CFG,学生本身不加 CFG;
- OPD 完成后再把 CFG 集成回学生。
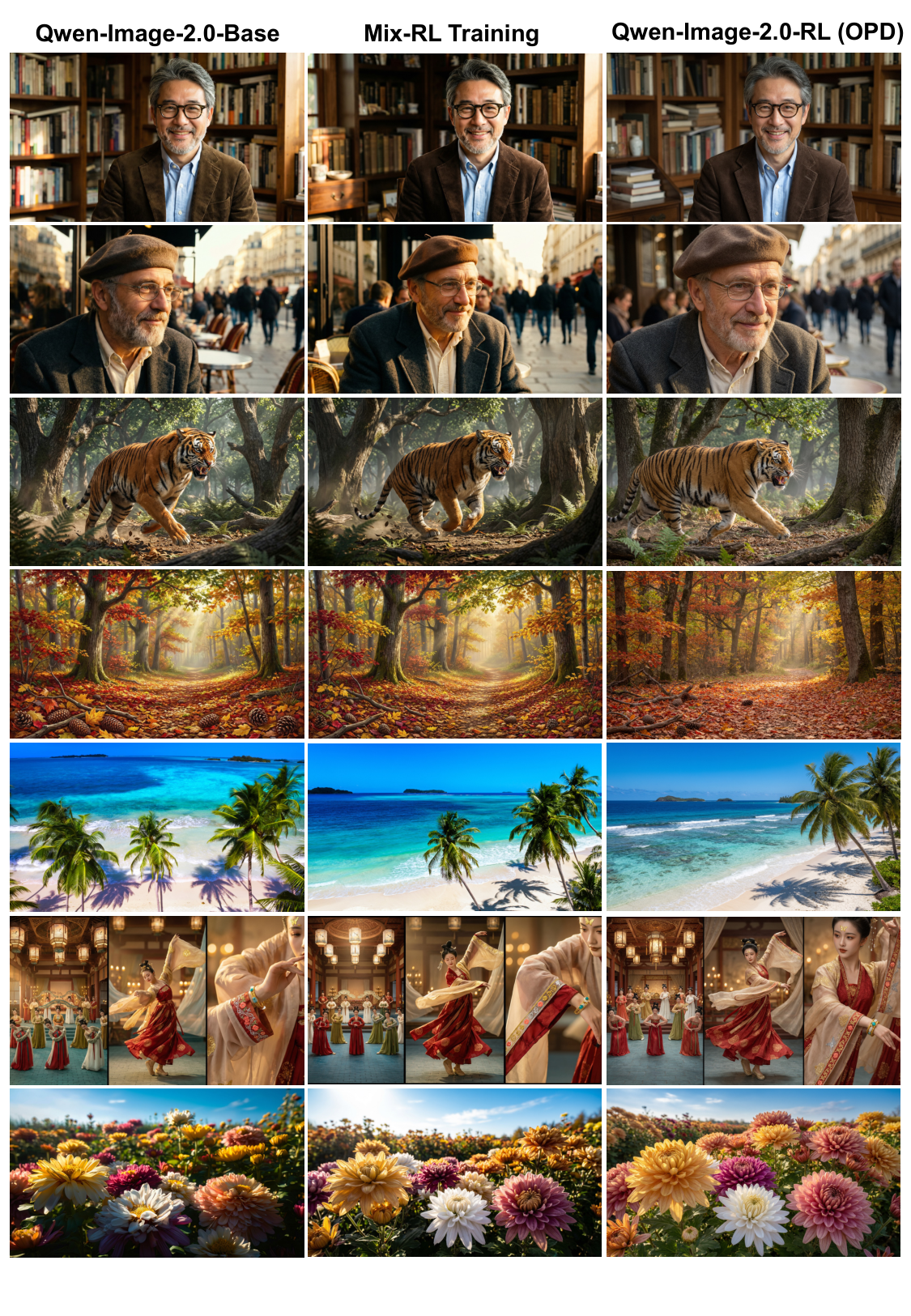
4.3.3 为什么不直接 Mix-RL?
一个直觉方案是把 T2I 与编辑数据混合训一个 RL 模型(Mix-RL)。作者三向对比 Base → Mix-RL → Qwen-Image-2.0-RL (OPD) 后发现:
- Mix-RL 相较 Base 已在纹理、构图、真实感上有提升;
- 但 OPD 一致性优于 Mix-RL——细节更锐利、指令遵循更准、美学更好;
- 编辑侧 Mix-RL 仍有 身份漂移或复杂指令不完整 的问题,OPD 版本显著优于两者。
解释:Mix-RL 强迫模型同时满足相互竞争的优化目标——OPD 通过把 RL 和跨任务合并两步解耦规避了这个 seesaw 效应。
4.3.4 目标的形式化推导(附录 A 精要)
作者用 2-Wasserstein 距离 而非 KL 作为学生-教师分布距离度量(KL 在扩散模型 path measure 上一般不可解):
由于直接算 W2 需要 optimal transport(高维不可行),作者引用 Benton et al. (2023) 的结论: 在 (A1) 光滑流的存在唯一性 与 (A2) 教师速度场 Lipschitz 连续 两个假设下,速度场近似误差可以给出 W2 的上界:
指数因子只依赖网络架构、与训练目标无关。因此最小化 W2 上界就退化成一个可计算的连续时间目标:
把连续积分离散化到学生自己的 N 步轨迹上,就得到 §4.3.1 的最终损失。
5评测 (Evaluation)
5.1 Qwen-Image-Bench 上的自动评测
Qwen-Image-Bench (Li 2026a) 是一个以创作者为中心的基准,覆盖 Quality / Aesthetics / Alignment / Real-world Fidelity / Creative Generation 五大一级支柱, 通过 Q-Judger 判官模型(在 130K 人工标注图-prompt 对上训练,标注人由 80 位专业艺术家组成)自底向上从 56 个三级 facet 聚合。
| Model | Quality | Aesthetics | Alignment | Real-world Fidelity | Creative Gen. | Overall |
|---|---|---|---|---|---|---|
| GLM Image | 49.26 | 50.64 | 47.90 | 44.69 | 45.23 | 48.19 |
| Kling Image 2.1 | 49.11 | 50.15 | 49.18 | 44.74 | 44.67 | 48.26 |
| Qwen Image | 48.44 | 52.25 | 50.72 | 43.16 | 47.30 | 49.23 |
| Imagen 4.0 | 50.16 | 52.68 | 51.64 | 44.84 | 47.94 | 50.29 |
| HunyuanImage 3.0 | 50.35 | 53.57 | 52.00 | 44.31 | 49.12 | 50.81 |
| Imagen 4.0 Ultra | 50.90 | 54.25 | 54.02 | 45.59 | 51.14 | 51.99 |
| Qwen Image 2512 | 51.76 | 54.74 | 52.72 | 47.00 | 50.19 | 52.06 |
| GPT Image 1 | 52.34 | 55.09 | 56.28 | 48.14 | 55.78 | 54.07 |
| FLUX 2 Pro | 52.30 | 56.94 | 57.01 | 47.29 | 56.18 | 54.57 |
| FLUX 2 Max | 53.64 | 56.85 | 57.35 | 49.35 | 56.50 | 55.33 |
| Seedream 4.0 | 54.01 | 58.81 | 56.64 | 51.05 | 58.15 | 56.21 |
| Seedream 4.5 | 54.41 | 58.72 | 57.31 | 51.69 | 60.64 | 56.78 |
| Seedream 5.0 | 52.55 | 58.40 | 58.90 | 51.92 | 65.29 | 57.22 |
| Nano Banana Pro | 55.67 | 60.26 | 61.25 | 54.07 | 66.23 | 59.45 |
| GPT Image 1.5 | 55.14 | 60.88 | 61.72 | 53.95 | 66.35 | 59.65 |
| Nano Banana 2.0 | 54.77 | 61.08 | 62.40 | 54.28 | 67.05 | 59.82 |
| GPT Image 2 | 58.65 | 67.53 | 65.85 | 57.38 | 75.23 | 64.69 |
| Qwen-Image-2.0-Base | 52.29 | 57.10 | 57.64 | 47.54 | 58.22 | 55.23 |
| Qwen-Image-2.0-RL (本文) | 54.39 | 58.67 | 59.28 | 51.83 | 64.94 | 57.84 |
表 1 · Qwen-Image-Bench 综合排名(分数为 [0,100],值越高越好 ↑); 橙色 = 榜首 GPT Image 2;绿色 = 本文 RL 结果。RL 训练相较 Base 在五大支柱上均有一致提升, Creative Generation +6.72、Real-world Fidelity +4.29 增幅最大。
5.2 人类偏好评测:T2I 与 Edit Arena
竞技场投票下的 Elo 评分:8 个子类别 + 总分。
5.3 定性对比:Base vs Mix-RL vs OPD

7结论 (Conclusion)
Qwen-Image-2.0-RL 展示了一条组合式的图像生成后训练路径——RLHF + OPD——同时提升视觉质量与指令遵循能力。三大贡献可概括为:
- VLM 组合奖励系统:既覆盖 T2I(美学 / 对齐 / 人像),又覆盖 TI2I(指令遵循 / 视觉一致性), pointwise + CoT 打分范式带来更丰富监督。
- 可扩展 GRPO 训练框架:hybrid CFG + 异步奖励管线让 flow matching 大规模 RL 训练成为工程上可行的方案。
- OPD 融合机制:以轨迹级速度场匹配把任务专用教师合并成一个部署模型;无需推理时依赖奖励模型, 同时保留了每个专业教师的能力。
定性与定量评估均确认:OPD 不仅匹敌而且超越了直接联合优化所有 reward 的 Mix-RL 基线。 最终系统在 Qwen-Image-Bench、T2I 竞技场、Edit 竞技场三个维度上均取得可观提升。
§关键概念速查表
§关键洞察与复现要点 (Reproducibility)
核心洞察 (Key Insights)
- Pointwise 打分优于 Pairwise:绝对分带来更 dense 的监督;相同数据池、相同架构下 RL 训完的图像质量差距明显(图 2)。 这与 LLM 领域主流用 pairwise 的经验相反,值得注意。
- Reward 越多,做归一化越关键:多 RM 加权前必须逐 prompt-group 各自归一化,否则量纲最大的 reward 会独占 advantage 信号。
- CFG 是预训练能力的载体:如果 RL 训练全程剔除 CFG,reward 涨、能力反而退化——CFG 对预训练知识的表达是必要的。
- Reward hacking 主要出现在低噪声时间步:只在高噪声(t 靠近 1)步做 RL 更新,能显著延后 reward 崩塌。
- 多任务合训 < 分头训 + OPD 融合:Mix-RL 的 seesaw 效应真实存在;解耦 RL 与融合两个阶段是更优方案。
- OPD 的目标本质是 W2 上界:在扩散 path measure 上 KL 一般不可解,W2 + 速度场匹配是自然替代。
- 教师带 CFG,学生不带:训练时学生保持无 CFG 更稳定;OPD 完成后再把 CFG 集成回去。
数据管线复现关键参数
| 组件 | 参数/取值 | 说明 |
|---|---|---|
| RM 输出空间 | {1,2,3,4,5} | token-probability 加权期望作为最终分数 |
| Pointwise 标注维度 | Quality + Fidelity | Likert 5 分;Quality 覆盖清晰/光照/色彩/风格/材质,Fidelity 覆盖结构/物理/伪影 |
| Pairwise 标注优先级 | 一致性 > 结构 > 纹理 > 美学 | 严格分层:上一层判决前不进入下一层 |
| T2I 奖励层级 | Alignment / Aesthetic / Portrait | 分层递进;对齐失败者美学分再高也封顶 |
| Edit 奖励层级 | Instruction + Face-ID | 指令拆解为 core + non-core,输出图三元组打分 |
| Portrait RM 数据源 | 高质量人像参考图 + 改写 prompt | 专注面部吸引力、皮肤/头发纹理,检查手指数/面部畸变 |
| Face-ID Reward | model-based embedding | 与 VLM 视觉一致性 reward 互补,捕捉细微身份漂移 |
模型 & 训练复现关键参数
| 组件 | 参数/取值 | 说明 |
|---|---|---|
| Base 模型 | Qwen-Image-2.0 (Zhao 2026) | flow matching 骨架 + VLM 条件编码器 |
| ODE Sampler 步数 | N = 40 | rollout 用完整 40 步;RL loss 只在子集上算 |
| 时间步子集偏好 | t 靠近 1 的高噪声步 | 抑制 reward hacking;主宰全局结构 |
| Advantage 计算 | 逐 RM 组归一化后加权 | Σ wk = 1;权重按 prompt 类别校准 |
| CFG 策略 | Rollout 用 / 训练目标不用 | hybrid 策略是训练稳定性的关键 |
| Prompt 过滤阈值 | 组内 reward 极差 > τ | 只保留有优化空间的样本;大幅提升训练效率 |
| 类别划分 | portrait / landscape / typography / general / ... | 每类分配独立 reward 权重向量 |
| 奖励服务部署 | 远程 API + 后台异步线程 | 把 RM I/O 隐藏在 GPU 生成之后 |
| OPD 教师数量 | 2(T2I + Edit) | 非激活教师 offload CPU;显存不随教师数线性增长 |
| OPD 学生 CFG | 训练无 CFG,训后集成 | 教师速度预测保留 CFG |
训练伪代码
# ================ Stage-1: 训练两个任务专用 RL 教师 ================ for task in [T2I, Edit]: reward_models = [load_RMs(task)] # T2I: {Align, Aesth, Portrait}; Edit: {Instr, FaceID} prompts = curate_prompts(task, base_model, reward_models, τ) # 极差过滤 weights = calibrate_weights(prompts) # 分类别 reward 权重 policy = clone(base_model) for step in range(N_STEPS): c = sample_prompts(prompts) # === Rollout: 用 CFG 生成 G 张图 (SDE 采样, 40 步) === images, traj = rollout_with_cfg(policy, c, G=G, T=40) # === 异步 reward: 后台线程调远程 API === R = async_score(reward_models, images, c) # [G, K] # === 多奖励优势 === A = group_norm_and_weight(R, weights) # 逐 RM 组归一化后加权 # === 时间步子采样 (偏高噪声) === t_subset = sample_high_noise_timesteps(traj) # === CFG-free 策略优化 (Flow-GRPO clipped surrogate) === loss = flow_grpo_loss_no_cfg(policy, traj, t_subset, A) optimize(policy, loss) save(policy, name=f"teacher_{task}") # ================ Stage-2: On-Policy Distillation 融合 ================ student = clone(base_model) teacher_T2I = load("teacher_T2I").to("cpu") teacher_Edit = load("teacher_Edit").to("cpu") for step in range(N_OPD_STEPS): batch = sample_mixed_batch() # 含 T2I 与 Edit 样本 # 学生解 ODE 保存自己的完整轨迹 (无 CFG) traj = student_solve_ode(student, batch, N=N) loss = 0 for sample in batch: teacher = teacher_T2I if sample.task == "T2I" else teacher_Edit teacher.to("gpu") # 只激活当前教师 for t_n in traj.timesteps: v_stu = student(traj[t_n], t_n, sample.c) # 无 CFG v_tea = teacher(traj[t_n], t_n, sample.c, cfg=True) # 带 CFG loss += (v_stu - v_tea).pow(2).mean() teacher.to("cpu") optimize(student, loss) # OPD 结束后再把 CFG 集成回学生 final_model = integrate_cfg_into_student(student)
复现常见坑
- 不加 hybrid CFG:只在 rollout 加 CFG 是非平凡但关键的选择——直接照搬 Flow-GRPO 会遭遇训练崩塌或能力退化。
- 时间步子采样不做:40 步全用会在几个 iter 内 reward hacking,需限定到高噪声子集。
- Reward 归一化位置:必须先逐 RM 组归一化再加权求和,反过来做会让量纲大的 reward 主导。
- Prompt 池不筛选:极差为零的 prompt 组占用 GPU 却不产生梯度信号——需按 τ 阈值过滤。
- OPD 阶段学生带 CFG:会破坏训练稳定;训练时无 CFG,训完再集成是关键顺序。
- 教师同 GPU 常驻:多教师同时驻 GPU 会撑爆显存;必须 CPU offload + 按需激活。
- Face-ID reward 缺失:只用 VLM 一致性 reward 不够——细微身份漂移无法可靠捕捉,编辑侧质量会打折扣。
- 忽视人像单独奖励:泛用美学 RM 无法覆盖手指数错误、面部畸变等具体故障,需单独训练 portrait RM。
§Q&A:读者常问的关键问题
Q1:为什么 pointwise 反直觉地优于 pairwise?LLM RLHF 主流是 pairwise。
作者的解释是:pairwise 只教「谁更好」,pointwise 教「一张图有多好」,这是校准过的绝对量。 在图像域,多数状态的样本已经"都不错",pairwise 退化成对纹理美学的直接比较,判断稀疏且噪声大; 而 pointwise 用 5 分 Likert 直接给出 dense scalar,advantage 信号更稳定。此外,pointwise 支持每个样本独立做 advantage, 而 pairwise 需要构造样本对,训练/推理阶段引入额外结构负担。作者用相同数据池、相同 VLM 架构做了对照实验(图 2)。
Q2:既然不加 CFG 会掉能力、加 CFG 会崩溃,为什么 hybrid 恰好可行?
Rollout 阶段用 CFG 是为获得可靠的 reward 信号——高质量候选让 RM 打分更有辨识度,避免 reward 噪声。 训练目标里剔除 CFG 是因为联合优化条件与非条件分支会引入梯度不一致,是崩塌的主因。 也就是说:CFG 在采样时是「能力扩音器」,在优化时是「不稳定源」——把它只保留在采样端就同时兼顾了两方面。
Q3:为什么 OPD 优于直接 Mix-RL?两种做法都是「合并两个任务」啊。
Mix-RL 让模型同时满足互相冲突的目标——T2I 要"生成锐利细节"、Edit 要"保留输入结构", 两个梯度经常互相抵消(seesaw 效应)。OPD 把这两步解耦:先各自把两个任务训到极致, 再通过轨迹级速度场匹配把两个专家「粘」到同一个学生里——学生只需要在自己走过的推理轨迹上模仿正确教师, 两个任务之间不再有梯度冲突。定性结果(图 5、图 6)明确显示 OPD 的复合能力优于 Mix-RL。
Q4:为什么用 W2 而不是 KL 作为学生-教师距离?
LLM 蒸馏用 KL 是因为 next-token 分布是离散且可枚举的,KL 能自回归展开。 扩散模型的输出分布是通过 ODE 隐式定义的连续 path measure,KL 一般不可解。 W2 在连续空间上有 Benton et al. (2023) 的速度场误差 → W2 上界结论: 只需匹配速度场就能间接压缩分布距离,且被压的 bound 里指数因子只依赖架构、和训练无关。 这样 OPD 的目标就退化为一个简洁的 velocity MSE,可直接优化。
Q5:hybrid CFG 已经是 clever 的选择了,还有别的做法吗?
还有一条思路是在 unconditional 分支上加正则或 KL penalty,让它不至于漂移,同时训练目标里保留两个分支—— DiffusionNFT 加 KL penalty 是这一思路的近似。缺点是需要额外算 unconditional 前向、显存和计算开销都翻一倍。 本文的 hybrid CFG 相当于一个更激进但更简洁的选择:直接在训练里干脆不算 unconditional, 靠 rollout 阶段的 CFG 提供"外部指导"。作者的实验证明这个更简的方案效果反而更好、更省算力。
Q6:Reward hacking 具体表现为什么?只在低噪声时间步才容易发生吗?
典型表现:图像变得平滑无纹理但 reward 却很高(RM 被局部纹理伪特征骗了),或过度饱和的色彩、过度锐化。 作者的观察:低噪声时间步(t 靠近 0) 主要塑造纹理与细节,此时 gradient 更容易走向 reward 特征捷径; 高噪声时间步(t 靠近 1) 主宰全局结构和语义布局,梯度更 semantic,走 shortcut 更难。 因此把 RL loss 限定在高噪声子集上更 robust。这条经验对其他扩散 RL 工作也有普适性。
Q7:Prompt curation 用「组内极差」当过滤指标,为什么不用平均分或方差?
「组内极差 = max − min」直接刻画了策略在这个 prompt 下有多大改进空间—— 如果 G 次 rollout 拿到的 reward 都差不多,说明策略要么已经很好、要么无论怎么试都不好,两种情况下更新都没意义。 平均分只反映"当前平均水平",方差反映"波动大小"(可能被离群点带偏),而极差是最直接的"能不能拉开差距"指标。 工程上也简单——不用考虑分布假设,一个减法即可。
Q8:为什么 Face-ID reward 必须是「model-based embedding」而不是继续用 VLM?
VLM 的 reward 本质是"生成一个语义描述再打分",语义级别的一致性它擅长——比如「同一个人」「戴着眼镜」这种概念。 但细微的身份漂移——两只眼睛的距离差 5px、下颌线弧度略变——不足以改变 VLM 的语义判断,却在人眼里非常明显。 基于 face embedding 的模型(如人脸识别 encoder)产生的距离在这些精细维度上灵敏得多,能补齐 VLM 的盲区。 所以两者互补而非替代。
Q9:这个方法能推广到视频扩散模型吗?
原理上完全可以——Flow Matching + GRPO 的骨架不区分模态,视频只是把 x 的维度加一个时间轴。 挑战主要在工程侧:rollout 时间成本会显著上升(视频扩散 ODE 步数往往更多),奖励模型也需要视频维度的评估能力 (如时序一致性、运动合理性)。此外 hybrid CFG 与时间步子采样的经验大概率仍然适用,OPD 融合也能自然扩展到"生成 vs 编辑 vs 视频延展"多任务场景。 作者未在本文验证,但这是一个自然的下一步。
Q10:Qwen-Image-2.0-RL 的最终结果距离 GPT Image 2 差 6.85 分,这个 gap 主要来自哪里?
看表 1 分维度:GPT Image 2 在 Creative Generation 上是 75.23,本文是 64.94(gap 10+); 在 Aesthetics 上 67.53 vs 58.67(gap 9);Alignment 65.85 vs 59.28(gap 6.5)。 也就是说 gap 主要在创造性生成和美学两个偏"主观质量"维度上——这两方面高度依赖预训练规模、数据多样性与规模化 RLHF 迭代。 本文的贡献主要是后训练阶段的方法论(+2.61 综合分),要缩小到榜首还需要底座继续升级。
§局限性与改进方向
数据层面局限
- Portrait RM 只用高质量人像参考图训练——覆盖低质量、异常构图(极端角度、遮挡、艺术化人像)时可能失效;
- Prompt curation 阈值 τ 未在论文中给出具体数值,且未评估 τ 对最终质量的敏感性;
- 标注人偏好(80 位专业艺术家)本身可能存在文化/审美偏差——非西方审美主导场景下的表现未验证。
模型层面局限
- Hybrid CFG 依赖预训练模型对 CFG 的表达——若 base model 本身对 CFG 敏感度低,此策略可能收益有限;
- OPD 需要维持两个任务教师的完整参数副本,虽然 CPU offload 缓解了显存但训练总时长仍上升;
- 时间步子采样具体选择哪些步、多少比例未给出方法论——实践中依赖调参;
- 论文没有报告 reward hacking 出现的具体训练步数,也没有量化子采样对稳定性延后的具体倍数。
基准层面局限
- Qwen-Image-Bench 与 T2I 竞技场的 Judger 都由本团队相关模型训练,存在潜在评测同源性偏差;
- 没有给出 Elo 评分的置信区间——78 与 93 的差距在不同投票量下可能不稳健;
- 所有对比模型的评测都基于某一版本的商业模型,可能不代表其后续更新版本;
- 没有OOD 泛化评测——对未见分布 prompt / 未见编辑指令的表现未知。
后续研究可行方向
- 视频扩散 + OPD:把方法迁移到视频;教师可拆成"运动一致性 / 视觉美学 / 时序连贯"多个专家。
- 更多任务的教师蒸馏:加入 inpainting、super-resolution、depth-guided 等专家教师,考察 OPD 的 scalability。
- 教师课程化:让教师随训练进度演化——早期偏"能力扩展"、后期偏"精修美学",避免固定教师带来的偏差。
- Reward Model 自动课程:根据学生当前弱项动态调整分类别 reward 权重,取代静态 per-category 校准。
- Reward hacking 早期检测:加一个"崩塌前兆"信号(例如 KL 到 base 的突增)作为训练自动 early-stop 触发器。
- 无 RM 的部署:本文 OPD 已消除推理时对 RM 的依赖,可继续研究"训练时 RM 也可减少数量"的方向。
- Pointwise vs Pairwise 的理论:论文只给了实证结论;从信息论或 SNR 角度解释绝对分优势将是有价值的补充工作。